A belated reflection on another aspect of PASIG17 from me today. I wish to consider aspects of “storage” which emerged from the three days of the conference.
One interesting one was the Queensland Brain Institute case study, where they are serving copies of brain scan material to researchers who need it. This is bound to be of interest to those managing research data in the UK, not least because the scenario described by Christian Vanden Balck of Oracle involved such large datasets and big files – 180 TB ingested per day is just one scary statistic we heard. The tiered storage approach at Queensland was devised exclusively to preserve and deliver this content; I wouldn’t have a clue how to explain it in detail to anyone, let alone know how to build it, but I think it involves a judicious configuration and combination of “data movers, disc storage, tape storage and remote tape storage”. The outcomes that interests me are strategic: it means the right data is served to the right people at the right time; and it’s the use cases, and data types, that have driven this highly specific storage build. We were also told it’s very cost-effective, so I assume that means that data is pretty much served on demand; perhaps this is one of the hallmarks of good archival storage. It’s certainly the opposite of active network storage, where content is made available constantly (and at a very high cost).
Use cases and users have also been at the heart of the LOCKSS distributed storage approach, as Art Pasquinelli of Stanford described in his talk. I like the idea that a University could have its own LOCKSS box to connect to this collaborative enterprise. It was encouraging to learn how this service (active since the 1990s) has expanded, and it’s much more than just a sophisticated shared storage system with multiple copies of content. Some of the recent interesting developments include (1) more content types admissible than before, not just scholarly papers. (2) Improved integration with other systems, such as Samvera (IR software) and Heritrix (web-archiving software); this evidently means that if it’s in a BagIt or WARC wrapper, LOCKSS can ingest it somehow. (3) Better security; the claim is that LOCKSS is somehow “tamper-resistant”. Because of its distributed nature, there’s no single point of failure, and because of the continual security checks – the network is “constantly polling” – it is possible for LOCKSS to somehow “repair” data. (By the way I would love to hear more examples and case studies of what “repairing data” actually involves; I know the NDSA Levels refer to it explicitly as one of the high watermarks of good digital preservation.)
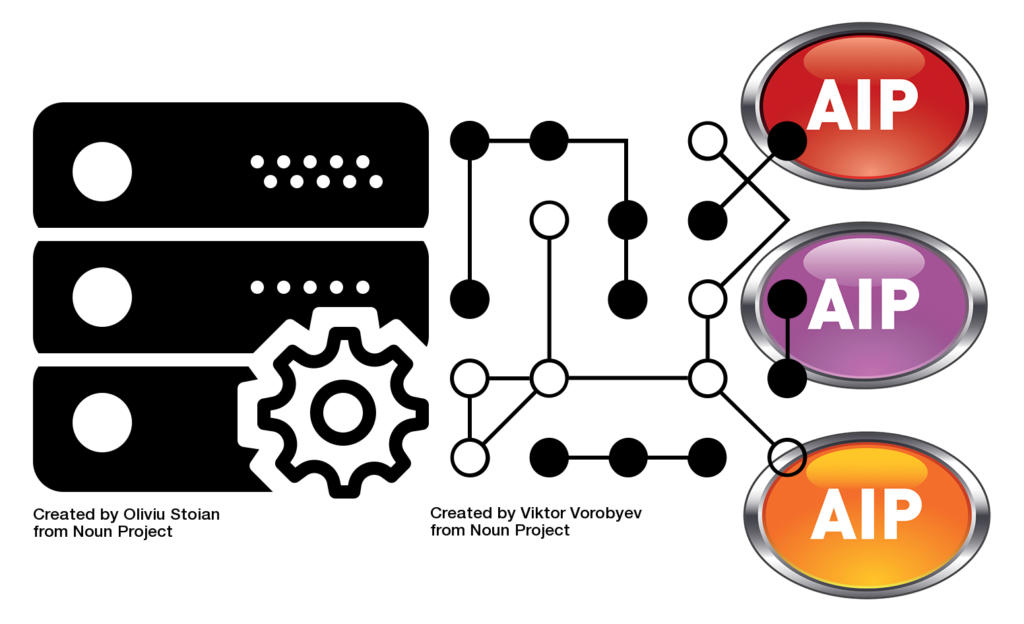
In both these cases, it’s not immediately clear to me if there’s an Archival Information Package (AIP) involved, or at least an AIP as the OAIS Reference Model would define it; certainly both instances seem more complex and dynamic to me than the Reference Model has proposed. For a very practical view on AIP storage, there was the impromptu lightning-talk from Tim Gollins of National Records of Scotland. Although a self-declared OAIS-sceptic, he was advocating that we need some form of “detachable AIP”, an information package that contains the payload of data, yet is not dependent on the preservation system which created it. This pragmatic line of thought probably isn’t too far apart from Tim’s “Parsimonious Preservation” approach; he’s often encouraging digital archivists to think in five-year cycles, linked to procurement or hardware reviews.
Tim’s expectation is that the digital collection must outlive the construction in which it’s stored. The metaphor he came up with in this instance goes back to a physical building. A National Archive can move its paper archives to another building, and the indexes and catalogues will continue to work, allowing the service to continue. Can we say the same about our AIPs? Will they work in another system? Or are they dependent on metadata packages that are inextricably linked to the preservation system that authored them? What about other services, such as the preservation database that indexes this metadata?
WIth my “naive user” hat on, I suppose it ought to be possible to devise a “standard” wrapper whose chief operator is the handle, the UUID, which ought to work anywhere. Likewise if we’re all working to standard metadata schemas, and formats (such as XML or json) for storing that metadata, then why can’t we have detachable AIPs? Tim pointed out that among all the vendors proposing preservation systems at PASIG, not one of them agreed on the parameters of such important stages as Ingest, data management, or migration; and by parameters I mean when, how, and where it should be done, and which tools should be used.
The work of the E-ARK project, which has proposed and designed standardised information packages and rules to go with them, may be very germane in this case. I suppose it’s also something we will want to consider when framing our requirements before working with any vendor.