This post is a response to a Tweet from Judith Dray seen recently. The plea was for a “cool, interesting, and accessible way to describe what an archivist does”.
I worked as a “traditional” archivist for the General Synod of the Church of England for about 15 years. When I say traditional, I mean I worked with paper records and archives. I could easily describe what I did in the usual terms, involving cataloguing, indexing, arrangement, description, and boxing of materials and putting them on shelves. In so doing, I would probably confirm the clichéd view that an archivist is a solitary hermit who loses themselves in the abstruse rules of provenance and original order.
But that misses the bigger picture. The work of an archivist only has any value if we put it in context. This context involves tangible things like other people, organisations, and the work and life of other people; and also involves abstract ideas, like culture, meaning, and history.

Below, I have written seven Tweetable responses to Judith Dray. But I had to unpack each Tweet into a paragraph of prose. I may have resorted to some hyperbole and rhetoric, but I like to think there is still a grain of truth in my ravings and fantasising. For this post, I have thought myself back into the past, and temporarily forgotten whatever I might know about digital preservation.
1. An archivist brings order to chaos.
Just give an archivist a random-seeming mess of unsorted papers and see how quickly that mess is transformed into an accessible collection. This is because archivist is applying sorting skills, based on their knowledge of parent collections, parent organisation, and former owners. Colleagues at the Synod sometimes assumed I was just “doing the filing”, but I think there’s more to it.
2. An archivist reflects the truth of an organisation.
If you want to know the core meaning, truth or essence of any organisation – from a business to a school to a textile factory – the archive holds the authoritative version of it. The archivist brings out that truth, through adhering to the fundamental principles of provenance (where the papers came from) and original order (how they were kept). These two principles may sound musty and boring, yet have proven surprisingly robust as a reliable method for reflecting the truth.
3. An archivist has the holistic view.
A good archivist isn’t just there at the end of the life of a record, but is there right at the start; they know the creators and understand precisely why they create the records that they do. In this way, they connect to and engage with the creating organisation in ways that surpass even the most diligent executive officer or auditor. The development of records management in the 20th century only served to strengthen this inherently archival virtue. At one stage in the 1990s, commercial companies tried to harness that rare skill and monetise it, turning it into something called “Knowledge Management”. Naturally, this failed!
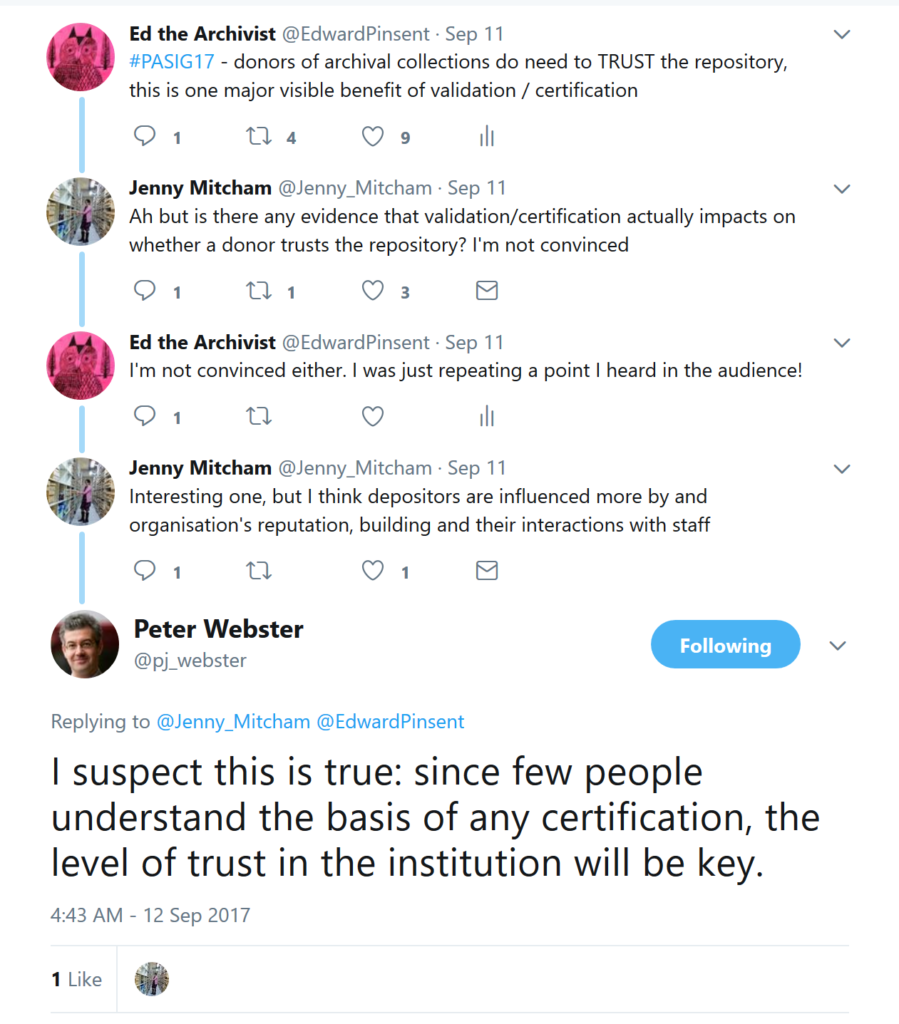
4. An archivist engenders trust in their depositors.
The real value of an archivist’s role has to be seen in the context of people and agencies who use archives. Among these people, the depositors, creators and owners of the resources are key. Over time the “culture” of archives has created and diligently nurtured a trust bond, a covenant if you will, that enables depositors to place their faith in a single archivist or an entire memory institution. That trust has been hard won, but we got there through applying effective procedures for due diligence, managing and documenting every stage in the transfer of content in ways that ensured the integrity of the resource, informed by the “holistic” skill (see above).
5. An archivist enables use and re-use of the archives.
A second key group of archive users comprises the researcher, the scholar, the historian, the reader. In today’s impoverished world the beleaguered archivist has been obliged to reframe “readers” as “customers”, seeing them as an income stream, but the cultural truth is much richer. Archives don’t change; but the historian’s interpretation of the source keeps evolving all the time. If any historian seeks to validate or challenge the interpretation of another, the archives are there – waiting silently for consultation. The same resource can be used to research multiple topics, depending on the “lens” the researcher chooses to apply; there is a well-known archival resource which began life as a land survey, yet in its lifetime it has been used as statistical evidence for population studies, income distribution, place names, family history, and more.
6. An archivist can beat Google hands-down.
In our insatiable lust for faster and deeper browser searches, we sometimes tend to overlook the value of structure. Structure is something an archivist has hard-wired into their genetic code, and it’s what makes archival cataloguing a superior way of organising and presenting information concisely and meaningfully. It’s not about sticking obstinately to the arcane rules of ISAD(G) or insisting on the Fonds-Series-Item hierarchy to the point of madness, but about understanding the structure of meaning, the way that one piece of information “belongs” to another, and how we can use these relationships to bring out the inner truth of the collection. Compared to this deep understanding, any given Google search return may give the user a quick hit of satisfaction, yet it is severely fractured, lacking in context, and disconnected from the core.
7. An archivist makes history manageable.
Any given archive probably represents a very small percentage of the actual records that were created at the time; this is especially true of any 20th century collection. Archivists are able to select the core 5% from this abundance, and yet still preserve the truth of the organisation. We don’t keep “everything”, to put it another way; we keep just the right amount. The skills of appraisal and selection are among the most valuable tools we have for any society that wants to manage its collective memory, yet these skills are taken for granted and under-valued, even by archivists themselves. We can feasibly scale this up to address the challenge of digital content. At a time when the world is creating more digital data than we can store or contain, let alone preserve, the skills of selection and appraisal will be needed more than ever.